
Кодирование текстовой информации
Цели:
-
Обучающие:
- понимать принцип кодирования текстовой информации;
- осознавать проблемы, связанные с кодировкой символов русского алфавита, и пути их решения;
- Развивающие: развивать внимание, логику;
- Воспитательные: воспитывать умение распределять время выполнения самостоятельной работы.
ХОД УРОКА
I. Организационный момент (1 мин)
Проверка готовности рабочего места (учебник, тетрадь, дневник, ручка, карандаш).
II. Актуализация опорных знаний
№2.
В кинотеатре 16 рядов по 32 места в каждом. Какое количество информации в битах содержит сообщение о том, что продан один билет в 8-м ряду место № 4?
1) 5 2) 8 3) 9 4) 16
N = 16 • 32 = 29
29 = 2I;
I = 9 бит
Ответ: 3
№10
В одном из способов представления Unicode каждый символ закодирован 2 байтами. Определите информационный объем следующего предложения в данном представлении:
Попрыгунья Стрекоза лето красное пропела.
1) 41 байт 2) 74 байта 3) 592 бита 4) 656 бит
Решение:
41 * 2 = 82 байта = 656 бит
Ответ: 4
III.Самостоятельная работа
Первый вариант
Задание 1.
Загадано число из промежутка от 1 до 64. Какое количество информации необходимо для угадывания числа из этого промежутка?
Задание 2.
При составлении сообщения использовали 128-символьный алфавит. Каким будет информационный объем такого сообщения, если оно содержит 2048 символов?
Задание 3.
Сообщение занимает 2 страницы. На каждой странице по 80 строк. В каждой строке по 32 символа. Найдите информационный объем такого текста, если при его составлении использовали 256-символьный алфавит.
Второй вариант
Задание 1.
Загадано число из промежутка от 1 до 128. Какое количество информации необходимо для угадывания числа из этого промежутка?
Задание 2.
При составлении сообщения использовали 64-символьный алфавит. Каким будет информационный объем такого сообщения, если оно содержит 3072 символа?
Задание 3.
Сообщение занимает 3 страницы. На каждой странице по 48 строк. В каждой строке по 64 символов. Найдите информационный объем такого текста, если при его составлении использовали 256-символьный алфавит.
IV. Изучение нового материала
Приложение. Слайд 1
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время)
занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, то есть I = 1 байт = 8 битов.
Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек
различает символы по их начертаниям, а компьютер - по их кодам.
При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу с символом, и в
компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт.
В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение.
Приложение. Слайд 2
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее). Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания. Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы.
Приложение. Слайд 3
Кодовая таблица - это таблица соответствий символов и их компьютерных кодов. Исторически сложилось так, что в России есть несколько несовместимых кодировок, то есть одинаковые символы имеют
различные коды в разных кодировках.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться
в другой.
Windows-1251 - набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно
отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO-8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует
только значок ударения); она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Имеет два недостатка:
• строчная буква я имеет код 0xFF (255 в десятичной системе). Она является виновницей ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также использующих этот код как
служебный;
• отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них
кодировок заметнее).
Для кодирования текстовой информации принят международный стандарт ASCII (American Standard Code for Information Interchange), в кодовой таблице которого зарезервировано 128 семиразрядных кодов для кодирования:
- символов латинского алфавита;
- цифр;
- знаков препинания;
- математических символов.
Для включения символов, например, русского алфавита возникла необходимость включения 8-го разряда, что позволило увеличить количество кодов таблицы ASCII до 255. Оставшуюся часть кодов
использовали для кодирования символов псевдографики, которые можно использовать, например, для оформления в тексте различных рамок и текстовых таблиц.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов,
а N = 216 = 65536 различных символов.
Процесс кодирования и декодирования является взаимообратной операцией. В схеме передачи информации должен присутствовать блок, отвечающий за кодирование передаваемого сообщения и за его декодирование
для получателя. В этом случае схема коммуникации выглядит так:
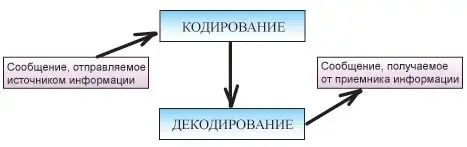
Полный набор символов, используемый для кодирования текста, называется алфавитом или азбукой. Этот алфавит представлен в кодовых таблицах.
V. Вычислительный практикум
- Сегодня мы займемся кодированием и декодированием текстовой информации, используя различные кодировки русского алфавита.
1. С использованием кодовой таблицы Windows (CP-1251) закодируйте слова «информатика», «АЛГОРИТМ», «система счисления».
2. Закодируйте с помощью кодировочной таблицы ASCII и представьте в шестнадцатеричной системе счисления следующие тексты:
а) Password; б) Windows; в) Norton Commander.
Ответ:
а) 50 61 73 73 77 6F 72 64;
б) 57 69 6Е 64 6F 77 73;
в) 4С 6F 67 69 6Е.
3. Декодируйте с помощью кодировочной таблицы ASCII следующие тексты, заданные шестнадцатеричным кодом:
а) 54 6F 72 6Е 61 64 6F;
б) 49 20 6С 6F 76 65 20 79 6F 75;
в) 32 2А 78 2В 79 3D 30.
Ответ:
a) Tornado;
б) I love you;
в) 2 * X + Y = 0
4. Декодируйте следующие тексты, заданные десятичным кодом:
а) 087 111 114 100;
б) 068 079 083;
в) 080 097 105 110 116 098 114 117 115 104.
В программе Блокнот набираем код на дополнительной клавиатуре при нажатой клавише Alt.
Ответ:
Word VOS Paintbrush
5. Представьте в форме шестнадцатеричного кода слово «БИС» во всех пяти кодировках.
6. Как будет выглядеть слово «диск», записанное в кодировке СР1251, в других кодировках.
VI. Инструктаж по выполнению домашнего задания
Задание: закодировать свое имя в двух кодировочных таблицах
VII. Итог урока (2 мин.)
Учитель: Мы учились кодировать и декодировать информацию, используя различные кодировочные таблицы русского языка.